
Ein Artikel der Sonntagszeitung zum Projekt Trainshare hat am Sonntagmorgen einen doch beträchtlichen Twitter-”Shitstorm” gegen die SBB ausgelöst. Als Beteiligter am Projekt möchte ich gerne schildern, wie es überhaupt so weit kam.
Der Hauptgrund für die Situation ist höchstwahrscheinlich ein Missverständnis am 30. März 2012: An diesem Datum fand in Zürich ein Open Data Hackday statt, ein Anlass an dem Programmierer, Designer und andere mit offenen Daten an tollen neuen Anwendungen für die Öffentlichkeit arbeiteten.
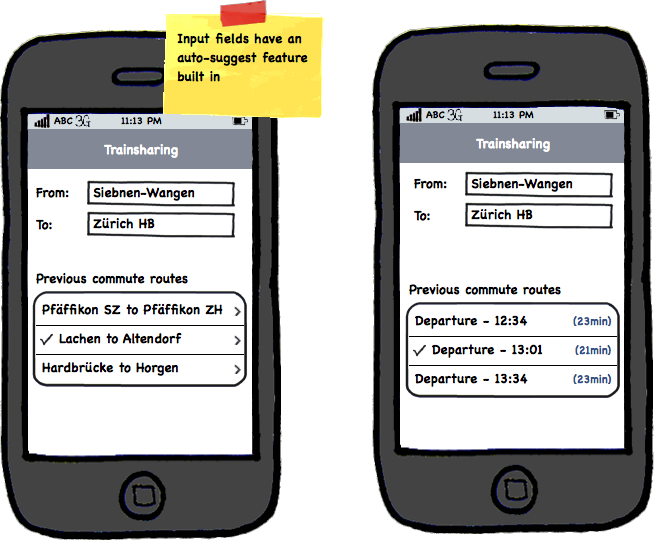
An diesem Event, nach einem vorhergehenden Blogeintrag, riefen Alain, Adrian und ich die Trainshare App ins Leben. Nachdem wir einen halben Tag daran gearbeitet hatten, setzten sich Bruno Spicher und Jean-Philippe Picard von den SBB zu uns, um mit uns zu diskutieren, worum es bei der Trainshare App geht. Ich erklärte ihnen ganz offen, was der Plan war und was unsere Beweggründe waren. Anschliessend liess uns Bruno Spicher wissen, dass sie “an etwas Ähnlichem” bauen, das im Herbst 2012 veröffentlicht werden solle. Diese neue SBB App werde gleich funktionieren wie die bestehende Gleis7 App, zusätzlich aber “CheckIns” erlauben. Tiefe “social media” Integration von Twitter und Facebook wurden weder im Gespräch erwähnt, noch gibt es derlei in der Gleis7 App.
Aufgrund der obigen Informationen beschlossen wir, die Trainshare App weiter zu entwickeln, und den Pendlern als kostenloses, werbefreies “social travel” Experiment anzubieten. Die anfallenden Daten wollten wir aufbereiten und visualisieren, sodass den SBB indirekt ebenfalls ein Nutzen erwächst – neben zufriedeneren Kunden vielleicht gar mehr Fahrten.
Über den genauen Inhalt der damaligen Gespräche besteht heute Uneinigkeit, rekonstruieren lässt sich die Sache kaum. Was ich aber tun kann, ist, die Geschehnisse nach dem Hackathon im März bis zum Sonntagszeitungs-Artikel am vergangenen Sonntag chronologisch aufzuführen – in der Hoffnung, dass sich daraus vielleicht etwas lernen lässt.
Chronologie der Geschehnisse
30. März 2012 - Hackathon
Nachdem wir uns unterhalten hatten, schrieb Bruno Spicher wohlwollend auf Twitter über @trainshare und erwähnte dabei Michael Rüetschli, den Projektleiter von @SBBConnect:
1. April 2012
Da wir unser Projekt während dem Hackathon nicht beenden konnten, schalteten wir kurz danach auf trainshare.ch eine E-Mail Sammelseite auf, die bis heute 200 interessierte Nutzer umfasst.
11. April 2012
Die Swisscom berichtet auf ihrem Blog über das @trainshare Projekt. Dies provoziert wiederum 18 zusätzliche Anmeldungen, was zeigt, dass wir eine Nische entdeckt hatten.
14. Mai 2012
Erste Anzeichen von @SBBConnect gesehen durch einen Retweet von @rueetschli. Nebenbei, wir beide folgen uns schon seit ca. einem Jahr gegenseitig auf Twitter:
18. Mai 2012
@SBBConnect ist ab jetzt nicht mehr nur ein Konzept, sondern wird gebaut. Hab mir damals nichts weiter dabei gedacht, da gemäss unserem Stand des Wissens @SBBConnect der Gleis7 App ähnlich sein wird, und wir mit der Twitter- und Facebook-Integration von @trainshare ein ganz anderes Publikum ansprechen werden:
28. Juni 2012
Hatte die Ehre und präsentierte @trainshare an der OpenData Konferenz 2012. Das Medienecho war gross und somit sollten auch bislang OpenData-fremde SBB-Mitarbeitende von der App Wind bekommen haben. Ein "Hallo, wir machen exakt dasselbe. Ihr könnt euch die Zeit also sparen" oder "Hi, wir finden es toll, lasst uns das zusammen bauen" oder jegliche andere Signale seitens der Bahn bleiben aus.
19. Juli 2012
Danilo, ebenfalls ein OpenData Hackathon Teilnehmer wies mich darauf hin, dass die @trainshare App Konkurrenz bekommt durch @SBBConnect. Als ich daraufhin den Artikel der Bernerzeitung las und sah, dass die App der SBB ebenfalls eine Integration der Sozialen Plattformen anbieten wird, bekam ich einen Schreck, da es doch hiess, sie soll wie die Gleis7 App werden:
Darauf kontaktierte ich die Team-Mitglieder Adrian und Alain und fragte sie, wie sie zu einer Beendigung unseres Projekts stehen. Dies, weil wir in einer Konkurrenzsituation die SBB niemals werbetechnisch hätten überbieten können und es keinen Sinn macht, eine Plattform für bloss ein paar Nutzer zu unterhalten. Zudem konnte es aus meiner Sicht nicht darum gehen, sich gegenseitig zu bekriegen, sondern darum, der reisenden Community einen Nutzen zu liefern.
20. Juli 2012
Da ich noch nicht von allen Team-Mitgliedern eine Antwort hatte und selbst unschlüssig war, wandte ich mich an den Opendata.ch-Vorstand, mit bitte um Rat. In der Diskussion wurde immer klarer, dass eine harte Konkurrenzsituation kaum etwas bringen kann– wie einige Jahre zuvor die App GottaGo gezeigt hatte.
23. Juli 2012
Das Trainshare-Team fällte – auch aufgrund des Falles von GottaGo – den Entscheid, das Projekt stillzulegen. Aber auch es wieder aufzugreifen, sollte die SBB App nicht machen, was wir uns wünschen. Zudem beschlossen wir, uns den SBB zur Verfügung zu stellen und nach Möglichkeit mit unserem Fan-Feedback mitzuhelfen, dass die App das wird, was sie sein könnte.
25. Juli 2012
Am Abend telefonierte ich mit dem Journalisten der Sonntagszeitung, und schilderte ihm meine Sicht der Dinge. Dabei ging ich noch immer davon aus, dass uns im März nicht kommuniziert worden war, dass die @SBBConnect App “social media” Integration haben würde.
26. Juli 2012
Der Journalist kontaktierte anschliessend auch Bruno Spicher von den SBB, um dessen Sicht der Dinge einzuholen. Da alles mit dem Gespräch im März begann, trug mir Barnaby Skinner danach die Worte von Bruno Spicher vor, um allfällige Diskrepanzen mit meinen Äusserungen zu finden. Dabei hiess es, Bruno Spicher habe mir gesagt, die SBBConnect App werde ähnlich der Gleis7 App werden, CheckIn Funktionalität sowie Social Media Integration bieten.
Meinerseits erinnere ich mich lediglich daran, dass es eine Gleis7 ähnliche App mit CheckIn Funktionalität und Coupons werden solle. Nachvollziehen lässt sich das nun kaum mehr.
Und jetzt?
Sicher hätte man vieles anders machen können. Aber das hilft dem Projekt nun nur noch wenig, entsprechend können wir nur nach vorne schauen. Ich persönlich hoffe, dass die SBB Führung die negative Stimmung im Nachgang zum Sonntagszeitungsartikel nicht als Normalfall in der Arbeit mit offenen Daten ansieht. Ich würde mir wünschen, dass sich daraus Lehren ziehen liessen für mehr Offenheit, für mehr Plattformdenken, wie etwa bei den Verkehrsbetriebe von San Francisco.
In diesem Sinne bitte ich euch Blogger und Twitterer alle, mit dem Shitstorm gegen die SBB aufzuhören. Und die SBB bitte ich ihr Bestes zu geben, um die optimale Version der @trainshare Idee umzusetzen, eine echt innovative “social travel” App!
Zudem nehme ich die öffentliche Einladung von @rueetschli, dem Projektleiter von @SBBConnect, gerne an und komme ihn in Bern besuchen:
Bezüglich den Lehren und einer Interpretation der Geschehnisse empfehle ich den Artikel von Hannes Gassert auf dem OpenData.ch Blog.
]]>
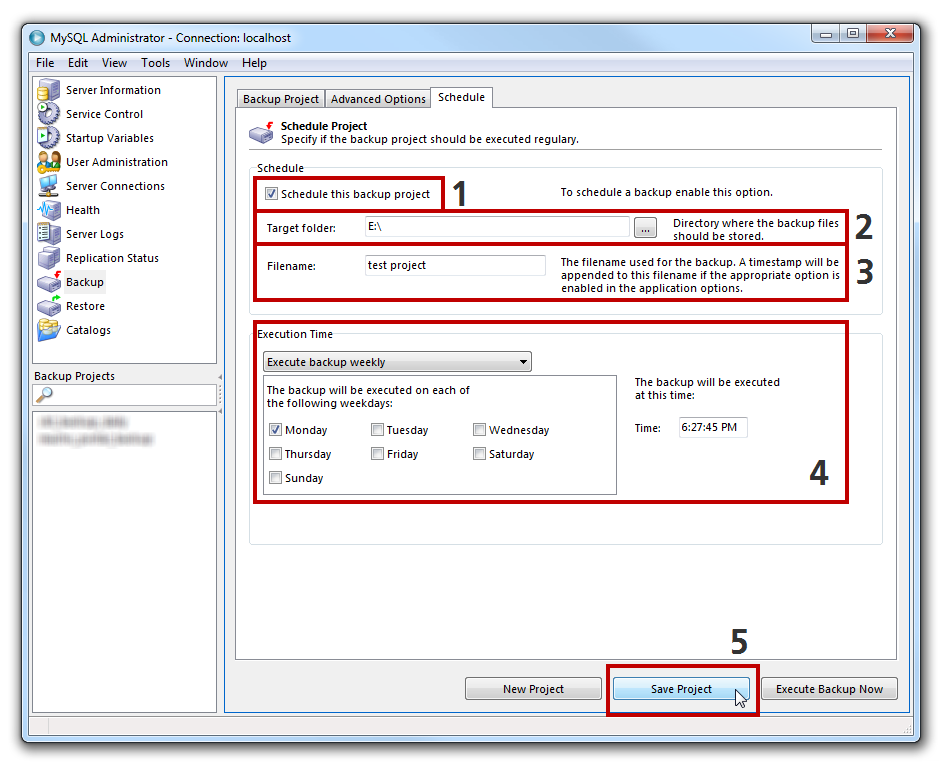
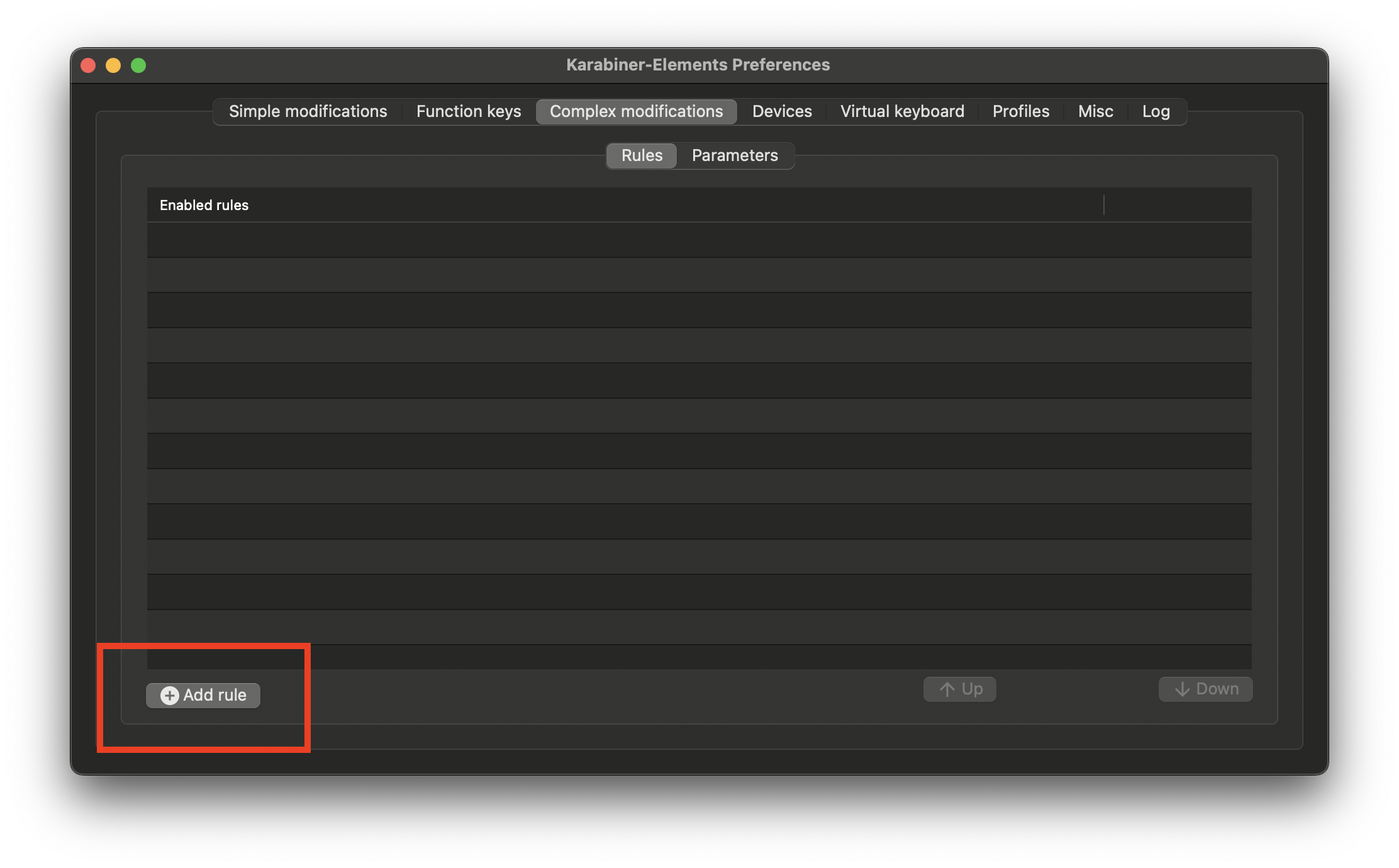 and there click the Enable button for the new configuration
and there click the Enable button for the new configuration 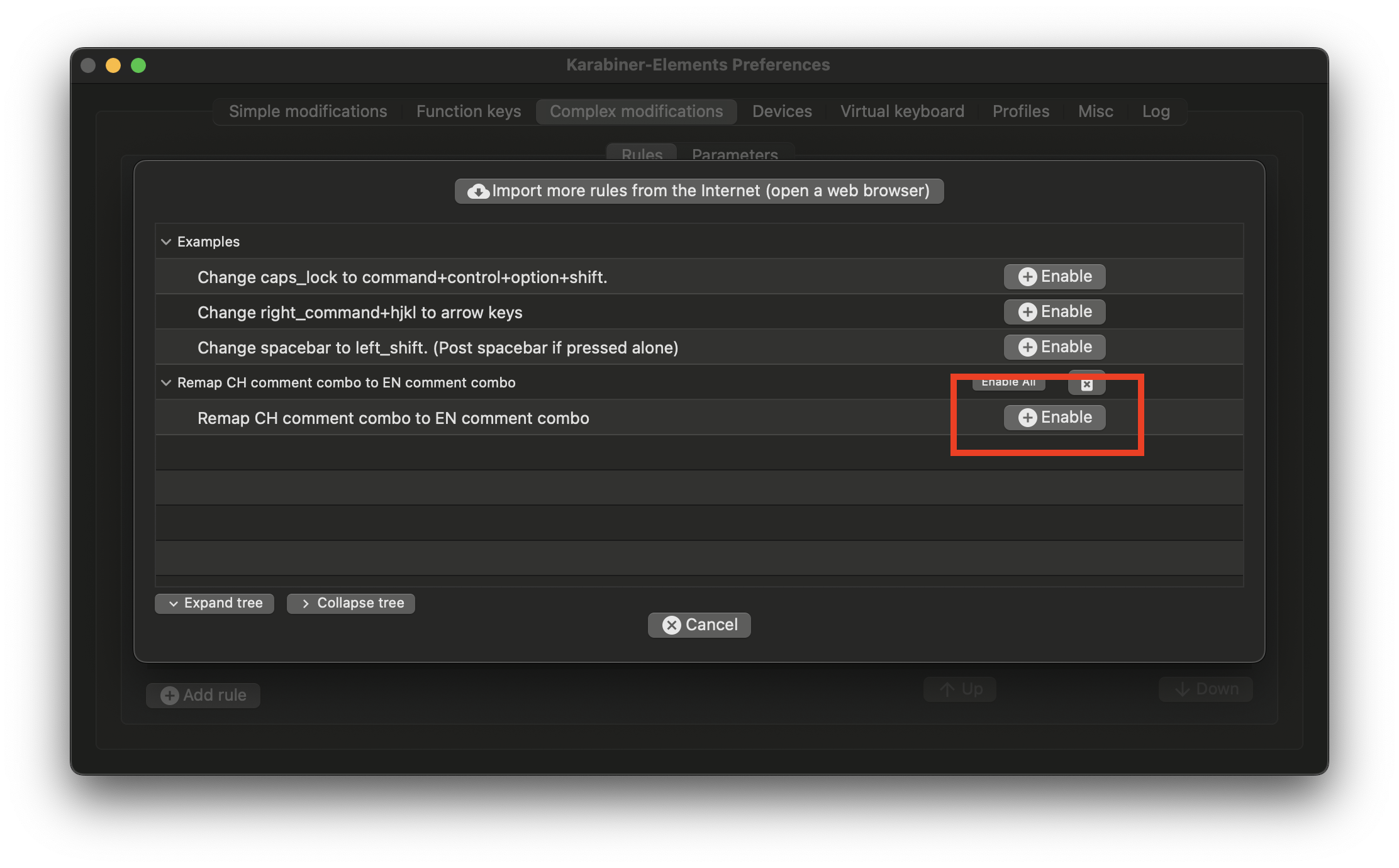 .
.





























![541444577_ffd86b5a25_b[1]](/assets/images/541444577<i>ffd86b5a25</i>b%5B1%5D.jpg)




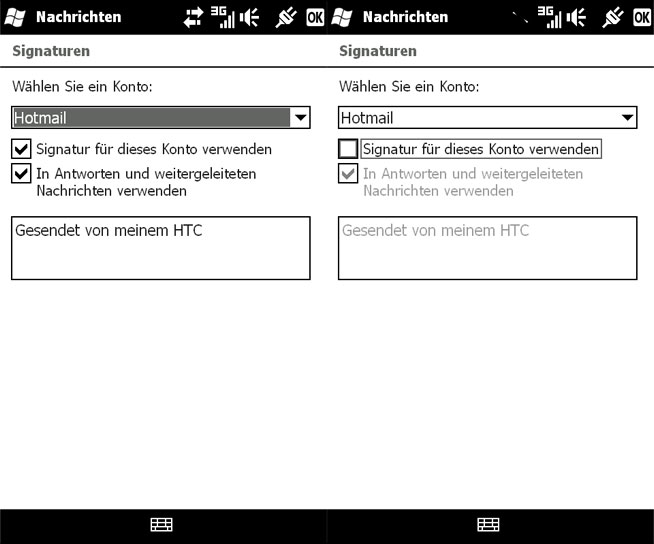
































 Yesterday my ZuneHD was delivered straight from the US. But unfortunately I wasn’t able to sync it with my computer (German Windows 7). After some research I stumbled upon this
Yesterday my ZuneHD was delivered straight from the US. But unfortunately I wasn’t able to sync it with my computer (German Windows 7). After some research I stumbled upon this 
 And now search for pfiles. You will find something like G:\PFiles. On my computer G was a virtual drive. So the solution was to deactivate all virtual and physical read-only drives and then try the installation all over again. This time it worked seamlessly.
And now search for pfiles. You will find something like G:\PFiles. On my computer G was a virtual drive. So the solution was to deactivate all virtual and physical read-only drives and then try the installation all over again. This time it worked seamlessly.